
But What is a Model?
Published:
In the last technical posts, where I was trying to figure out whether my model was ready to be compared or not, I realized that it was never really about comparisons! A model is not intrinsically good or bad; rather, the setup is either a match or not. When I tried to see how cross-validation helps me evaluate my model, the answer was the same: a model is not the only thing to be evaluated; it is the whole setup. So, what is a model exactly? And how does one know when it is a match or not?
To help myself understand what a model is, I will go, as usual, elemental. I will try to see what the simplest possible form of a model is, and build my intuition about it one step at a time.
What is a model?
A model is a tool that uncovers (models) a relationship between two things.
Let us think about feelings and behaviors, for example. I believe we can agree that there is a relationship between them. If someone is angry, they are more likely to be fidgety and make their surroundings reactive. If someone is relaxed, they are more likely to stay in a confined space and move smoothly.
The ability to describe this sequence of angry → reactive, relaxed → smooth, etc., is exactly what a model does. It finds a relationship that maps between something (feelings) and another thing (behavior).
This mapping and this relationship are what any model is trying to express. And this relationship can range from simple to intricate.
Different types of things (variables)
The possible relationships that can exist between two things begin by identifying the type of these two things. In the lingo of machine learning, a thing that can have different outcomes is referred to as a variable1.
There are two main classes used to describe a variable: qualitative and quantitative. Each of these classes restricts the way one might think about relationships. Therefore, they restrict what a certain model can do about them.
Let us further explain these classes.
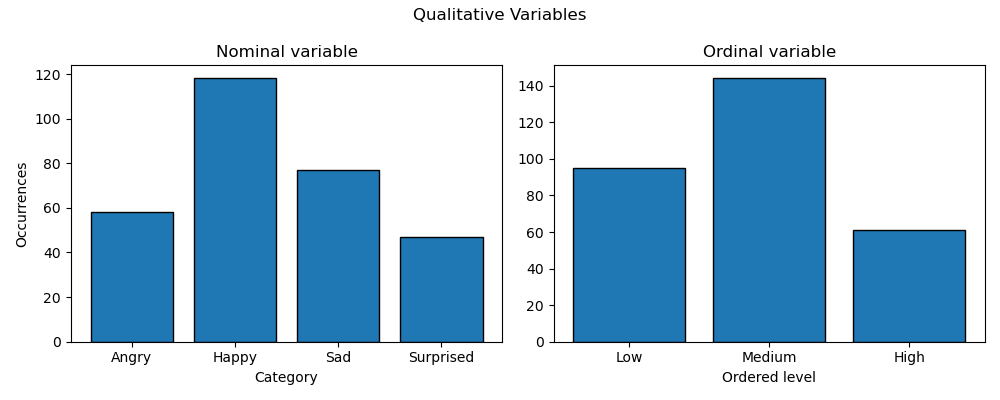
Qualitative variable
Qualitative variables describe an entity outside the numerical realm. They obey simple mathematical operations strictly contained within the realm of discrete mathematics. These qualitative variables split into two categories.
- Nominal (i.e., orderless descriptors like happy, angry, or cat, dog): These descriptors merely name things. They do not have notions of order, magnitude, or spacing.
- Ordinal (i.e., ordered descriptors like low, medium, or neutral, good): These descriptors are also merely names, but they have order (i.e., medium is “higher” than low) and spacing (i.e., medium is in the middle of low, medium, and high). However, the spacing is not quantified (i.e., one does not know what the “distance” between
lowandmediumis).
The mathematical operations one can apply to nominal variables will be things like logical operations (e.g., NOT, AND, OR, XOR), set theory (e.g., \(\cup\), \(\cap\), \(\subset\)), graph theory, and discrete probability. Things can happen together, partially, or not happen. They can happen together equally or conditionally. And so on.
With ordinal variables, the same operations apply, but now one can add comparison operations (e.g., \(>, <, \ge\)).
Quantitative variables
The other class of variables is the numerical one. This is where math can do its full magic! But one still needs to be careful about which math does which magic.
The number line stretches from \(-\infty\) to \(+\infty\) with all possible numbers. And math is most powerful when it deals with the full rich spectrum of the number line. However, not all numerical variables span these numbers.
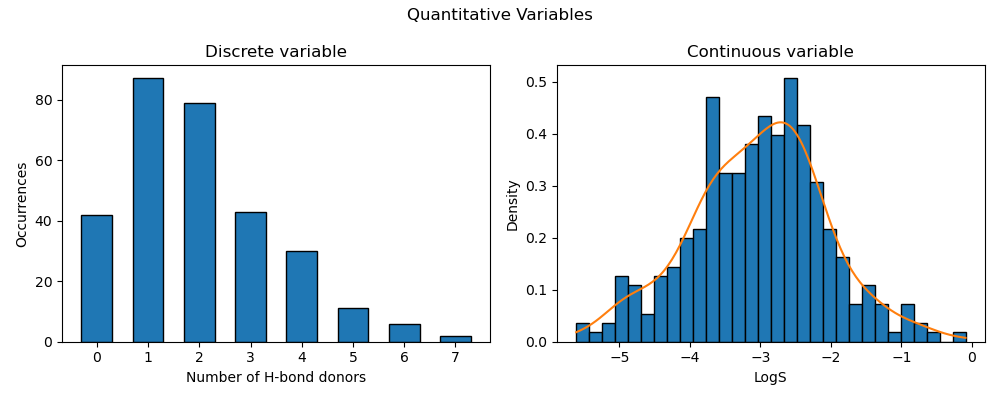
Quantitative variables generally split into two categories.
- Discrete: The values jump from one number to another rather than spanning the full numerical spectrum in between.
- e.g., counting the number of people in a room. It will always be strictly natural (i.e., positive integers) because there are no such things as 0.5 individuals.
- Continuous: The values span the whole spectrum of an interval.
- e.g., temperature in °C. A temperature can be 25, 25.2, 25.58, etc. All real values between any two intervals are possible.
The importance of understanding this distinction in quantitative variables lies in determining which math one can use: discrete mathematics (extended beyond qualitative variables) or calculus.
Discrete variables still resemble qualitative variables in a sense. They still capture a variable in terms of pieces (e.g., instead of low, medium, high, … it becomes 1, 2, 3, …), but with added functionality. Now, one can do mathematical operations like addition, subtraction, or division, and the result will be producible and meaningful.
For continuous variables, it becomes intuitive to use calculus concepts like derivatives and gradients. For those familiar with machine learning lingo, and especially deep learning, these words are a buzz.
Another categorization of quantitative variables, which can work with both discrete and continuous categories, is:
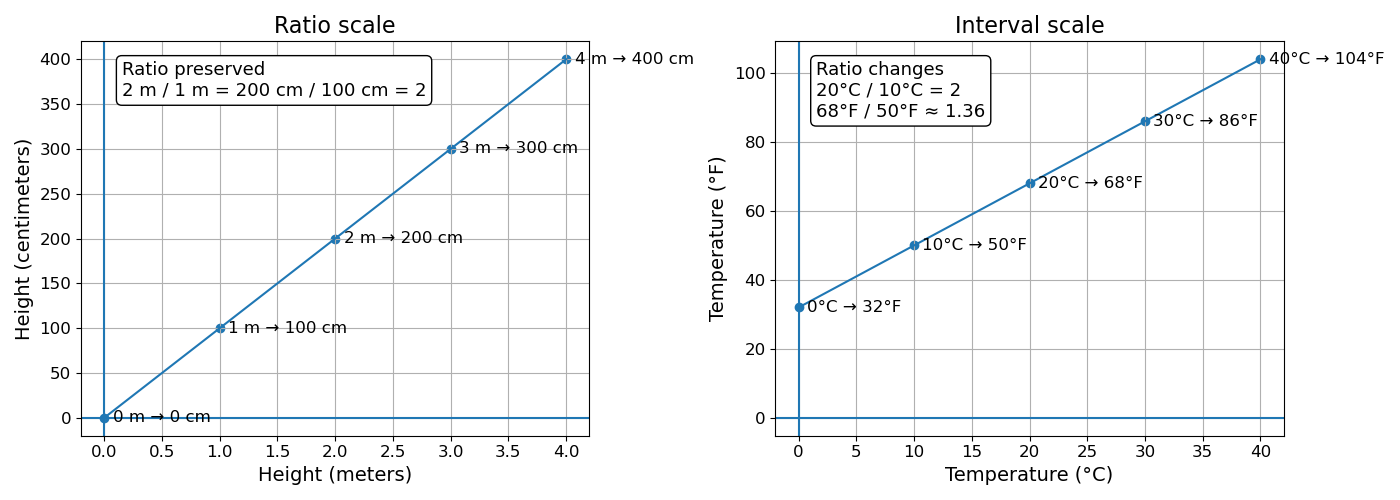
- Ratio (scale invariant): The values lie on a scale where zero is a true zero and means “none of this thing.” Therefore, ratios are meaningful.
- e.g., a tree that grows from 1 m to 2 m has “doubled” in height. This doubling means the same thing regardless of the unit used to measure height (e.g., centimeters, feet, or inches).
- Interval (scale variant): The values lie on a scale with equal spacing but an arbitrary zero point. The zero does not represent “none of the thing”—it is simply a chosen reference. As a result, ratios are not meaningful.
- e.g., for temperature, on the Celsius scale, zero means frozen water, not “no temperature.” If I have a temperature of \(10^\circ C\) and I want to “double” the temperature, this does not have a clear meaning because \(10^\circ C\) does not mean 10 units of heat; it merely means 10 units away from the arbitrarily chosen reference. So, performing an equation like \(2\times20^\circ C\) does not double the temperature; it doubles the distance from that reference point.
- To anchor the meaning in different scales, \(20^\circ C / 10^\circ C = 2\), but the same temperatures expressed in Fahrenheit become \(68^\circ F / 50^\circ F \approx 1.36\). The meaning of the ratios is not anchored because the scale is arbitrary.
Differentiating between when a variable is ratio or interval is also important in determining which level of math is possible to apply. Any math that requires a clear and correct definition of zero, and therefore ratios, will not be “intuitively applicable” to an interval variable (e.g., proportions, exponential functions, and logarithmic functions).
Different types of relationships (functions)
Now that I know my variables, the next step is to know my “relationships.” In the field of mathematics, this is well known by the name of “functions.”
A relationship is established between at least two elements; here, it will be two variables. And following the traditional lingo, they will be named X and Y. A function is the relationship that will show me whether there is a way to map from the variable X to the variable Y. The traditional equation is
\(Y\) and \(X\) represent the full variables with all possible outcomes, while \(y\) and \(x\) represent specific values of the variables.
E.g., \(Y=[2, 4, 8, 10]\) and \(X = [0.2, 0.4, 0.8, 1]\). Then the relationship between any pair of values in both variables (e.g., \(y=2\) and \(x=0.2\)) is 10 (i.e., \(y = 10x\)).
The goal everyone chases in the fields of mathematics, statistics, and supervised machine learning is to find the “right” \(f(x)\) for a given \(y\). The candidates for such a function can be vast (Figure 4), spanning linear relationships2:
\[f(x) = ax + b\]Non-linear relationships:
\[f(x)= x^a,\text{ }f(x)=\log(x),\text{ }f(x)=\operatorname{softmax}(Wx + b),\dots\]Or a mixture of linear and non-linear relationships:
\[f(x)=ax + bx^a + c,\text{ }f(x)=ax + \log(x+b) + c,\dots\]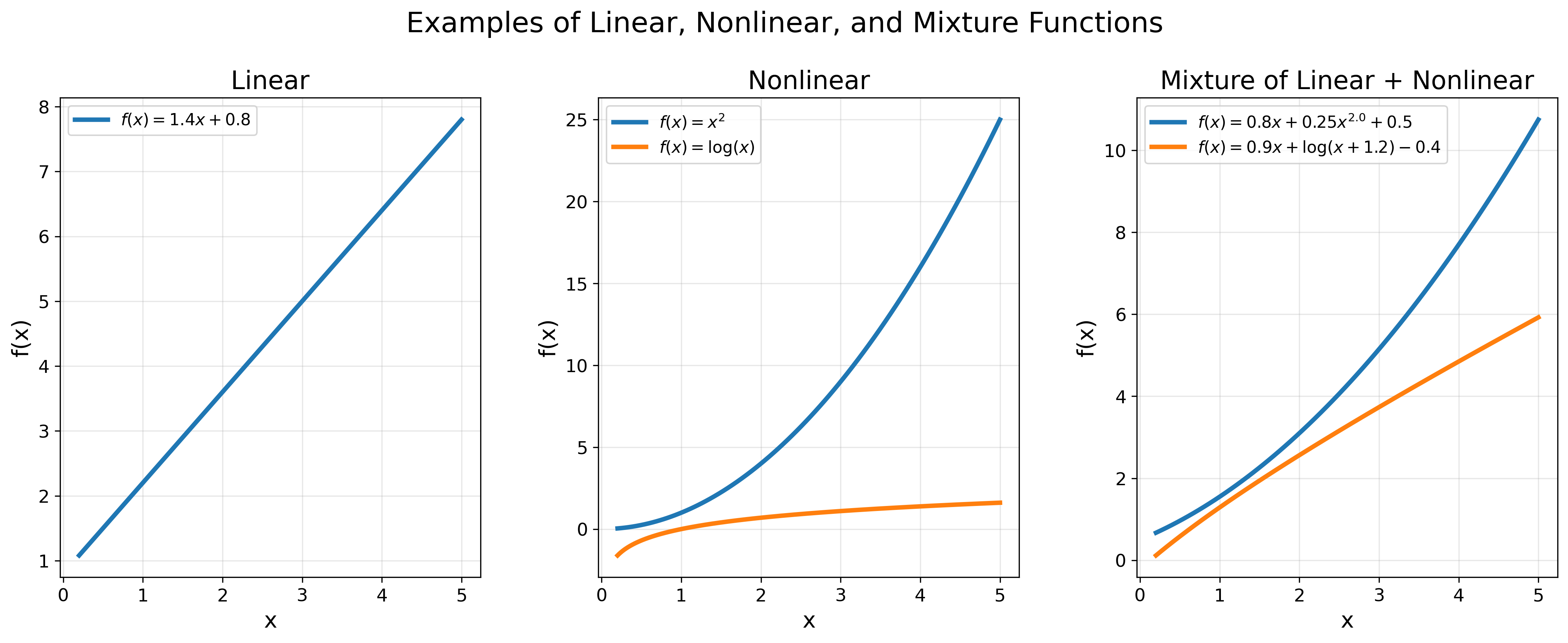
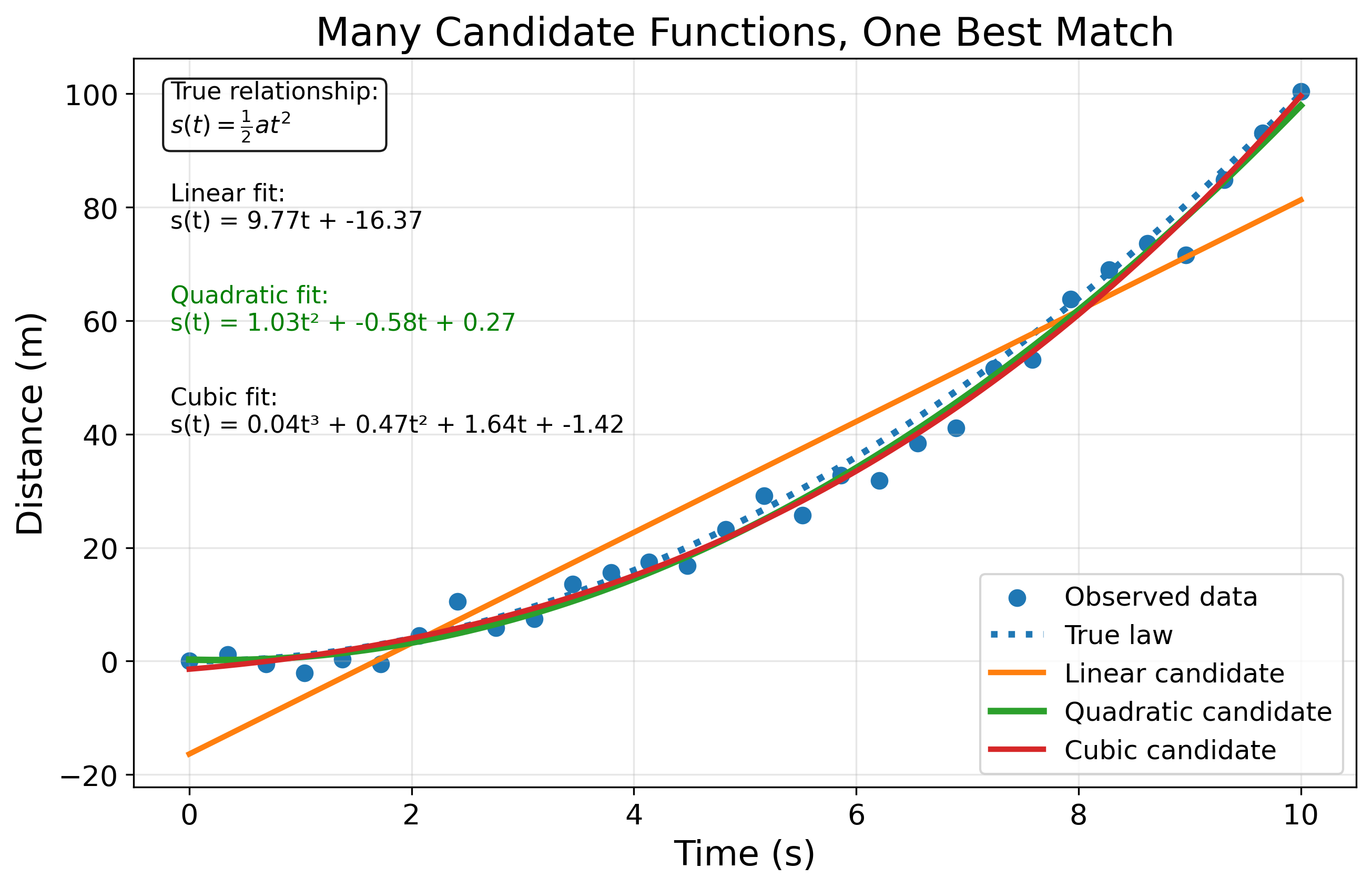
The way to decide which function is the “right” one for a given \(X\) and \(Y\) is to plug in each \(x\) and \(y\) and see which function gives the (almost) right answer. Check Figure 5 for a simple example of competing functions describing the displacement equation.
While the exploration space of \(f(x)\) can span infinitely many shapes, the type of the variables can help limit this space. This limitation starts by defining whether both variables share the same type (e.g., both nominal or both continuous), or whether they differ from each other (e.g., \(X\) is nominal and \(Y\) is continuous).
\(X\) and \(Y\) are the same
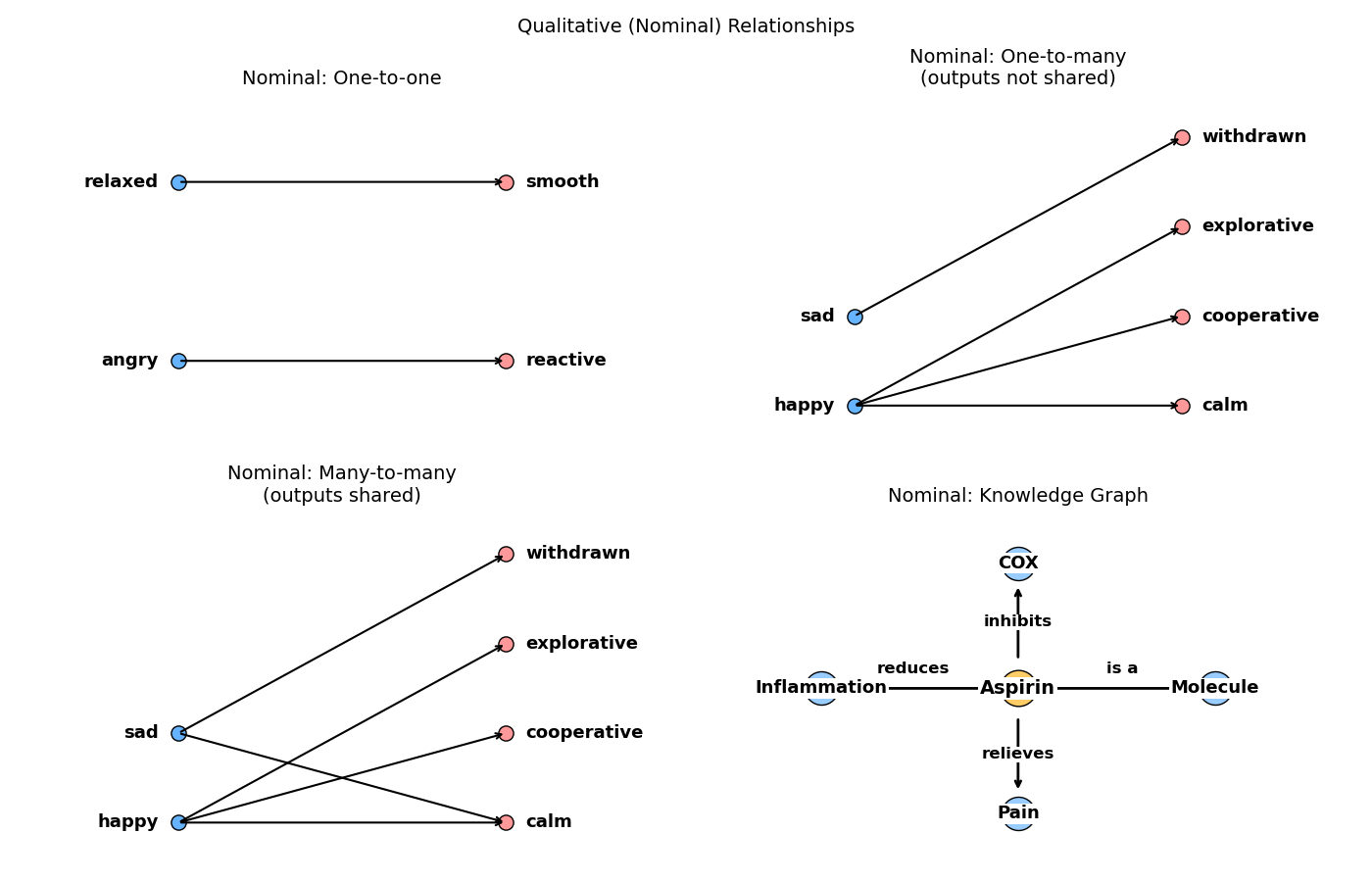
If both variables are nominal, for example, then the function will be rule-based (i.e., if \(X=x\) then \(Y=y\)).
These rules can also come in different flavors: one-to-one mapping, one-to-many, or many-to-many. And if the number of variables is higher than two, one can start drawing a graph and connecting the concepts like a mind map. Check Figure 6 for visuals.
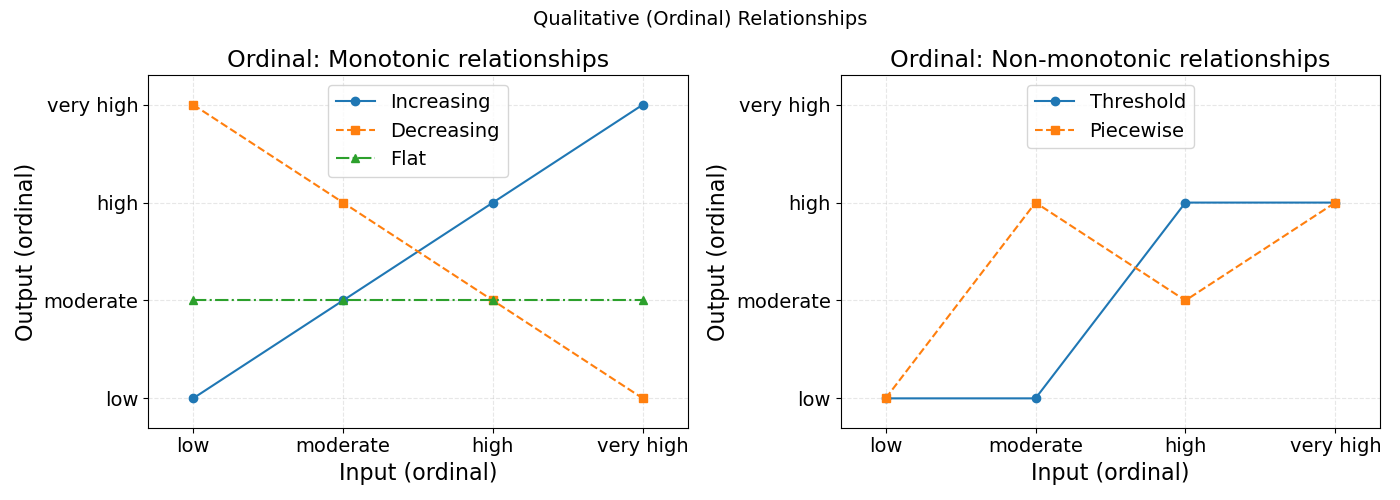
If the two variables are ordinal, then values have a specific order of appearance, and this changes what the relationship can look like. Now, relationships move from rule-based to threshold-based (e.g., if \(X<x\) then \(Y \ge y\)).
The ordering also allows for monotonic relationships, where the two variables can increase/decrease together or against each other. Check Figure 7 for visuals.
If the two variables are quantitative, one has two categories, discrete and continuous, and two subcategories, interval and ratio.
Discrete interval variables expand on ordinal variables by having equal spacing (i.e., distance), which allows for additions and subtractions. This further allows for arithmetic operations like deviation (i.e., subtracting values from the mean) and covariance (i.e., checking whether deviations move together).
I tried to find two variables that are discrete and interval put into a relationship together, but I could not find a meaningful or interesting example. So, I will speak about two interval variables, generally either discrete or continuous.
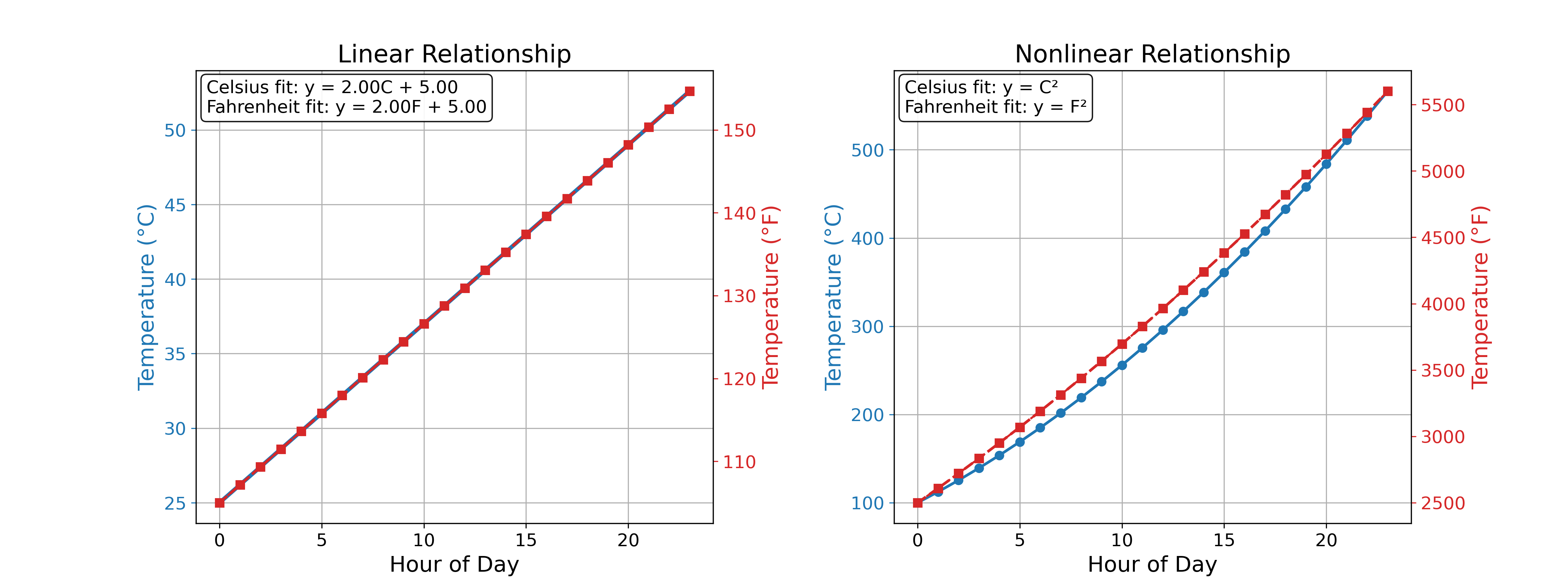
These interval variables are most naturally interpreted through linear functions such as \(y = ax + b\). This equation simply says that if \(X\) were a differently scaled version of \(Y\), it would be scaled by the factor \(a\) and shifted by the offset \(b\). This is exactly the case between the Celsius and Fahrenheit temperature scales, for example (\(C = \frac{5}{9}(F - 32)\)).
However, a function like \(y = ax\) or \(y = x^a\) or any other non-linear function would fail to produce a meaningful result without caution. This is because these functions rely heavily on the value of \(x\) having an intrinsic meaning, which makes manipulating it also meaningful. However, since the scale of \(X\), and therefore the values \(x\), is arbitrary, they are not easily manipulated in a meaningful way.
Recall the temperature and height examples in Figure 3: doubling the temperature on the Celsius scale is not the same as doubling the temperature on the Fahrenheit scale. However, doubling the height on the meter scale is the same regardless of any other ratio scale used.
Figure 8 further reinforces this distinction with an example of how a linear relationship preserves the meaning between two interval scales while a nonlinear relationship diverges.
To relax the strictness of “non-linear transformations are not meaningful,” one can say they are, under strict and clear communication of the meaning of this transformation.
- Clearly communicate that the transformation is meaningful only from the arbitrarily chosen reference, not from the value itself.
- Clearly communicate that the transformation is strictly valid for this scale, not any other.
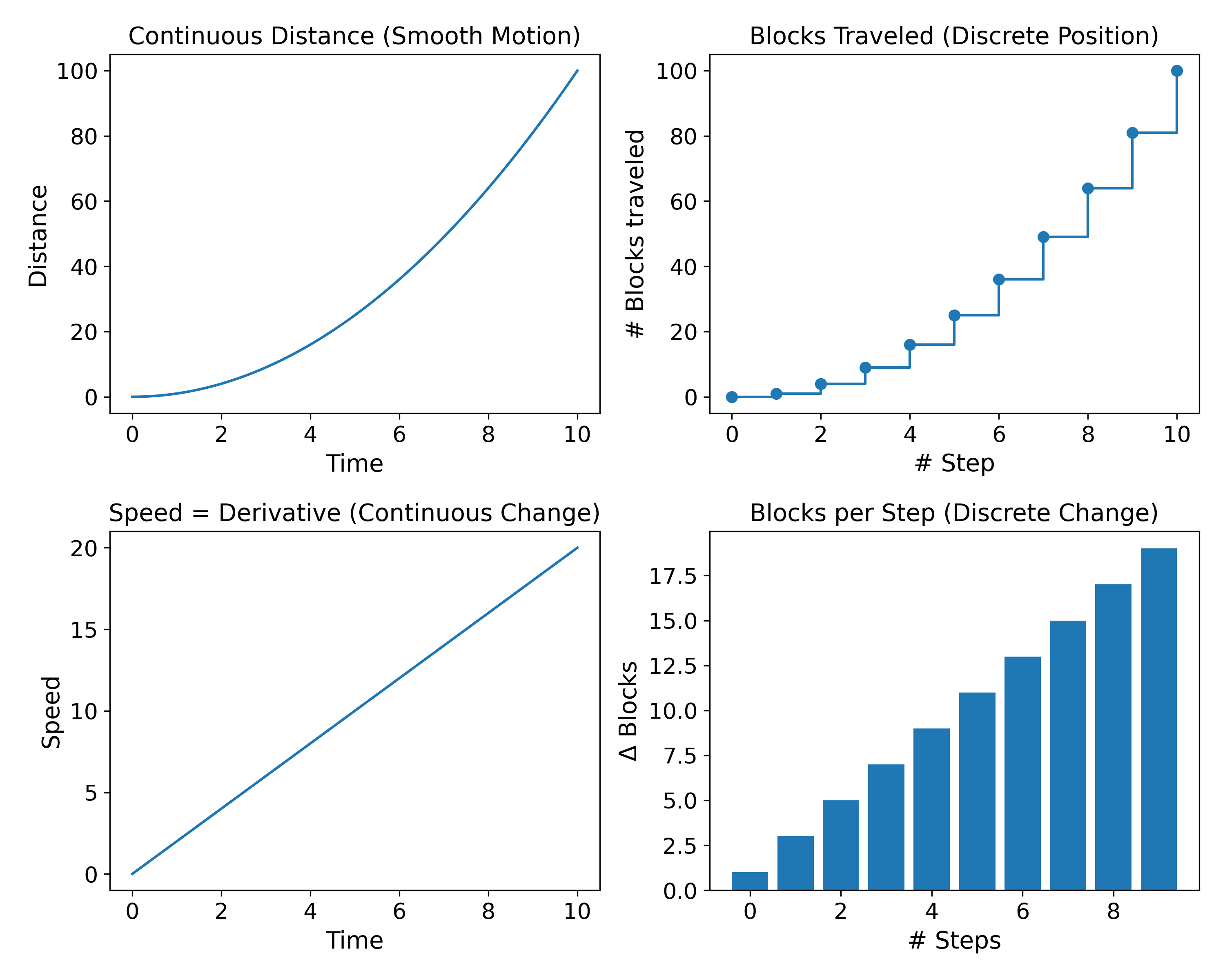
Continuous interval variables follow the same rules (i.e., additions, subtractions, linear relationships), but the difference lies in how changes are expressed mathematically (Figure 9).
For discrete variables, accumulation is represented by summation \(\sum_{i=1}^{n} x_i\) whereas for continuous variables, accumulation is represented by integration \(\int_a^b f(x)\,dx\).
Similarly, change between discrete points is expressed with simple differences such as \(\Delta y = y_{i+1} - y_i\) whereas continuous change is expressed using a derivative \(\frac{dy}{dx} = \lim_{\Delta x \to 0} \frac{\Delta y}{\Delta x}\).
Thus, discrete interval variables typically lead to difference equations, while continuous interval variables allow the use of differential equations, including derivatives and integrals.
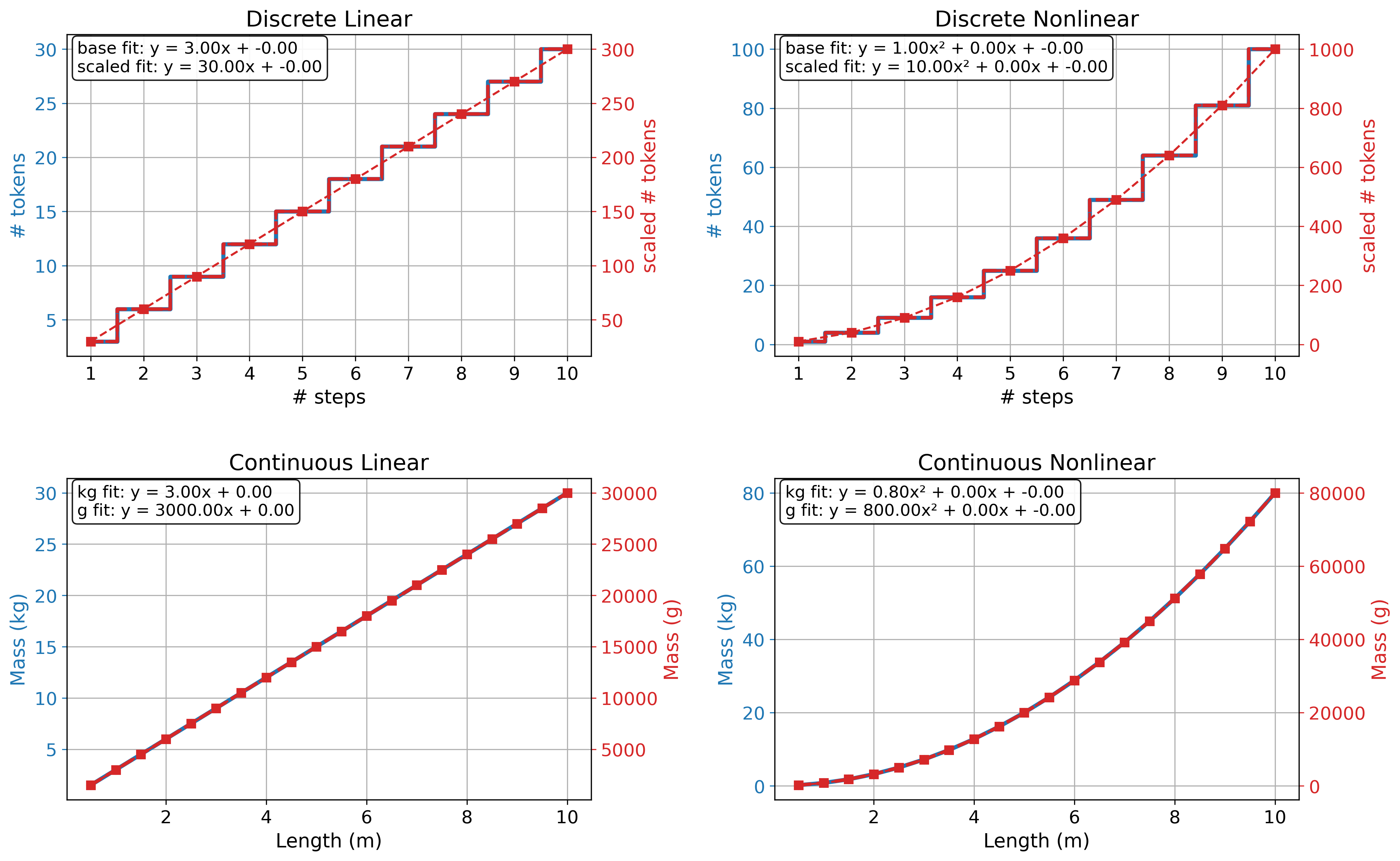
If the two variables are discrete ratio or continuous ratio, then the function can safely take other shapes with meaningful interpretations, like proportions (i.e., \(y = ax\)), exponential (i.e., \(y = x^a\)), logarithmic (i.e., \(y = \log(x)\)), or any other transformation.
The difference between the two variables remains in the sense that a discrete ratio variable will stick to discrete math, while a continuous ratio variable will allow calculus (Figure 10).
\(X\) and \(Y\) are different
If the variables differ from each other in type, this leads to interesting cases because, as I have explored, each variable allows for certain functions. When variables agree, the math used is unified, but what happens when they disagree? Would the math still work seamlessly?
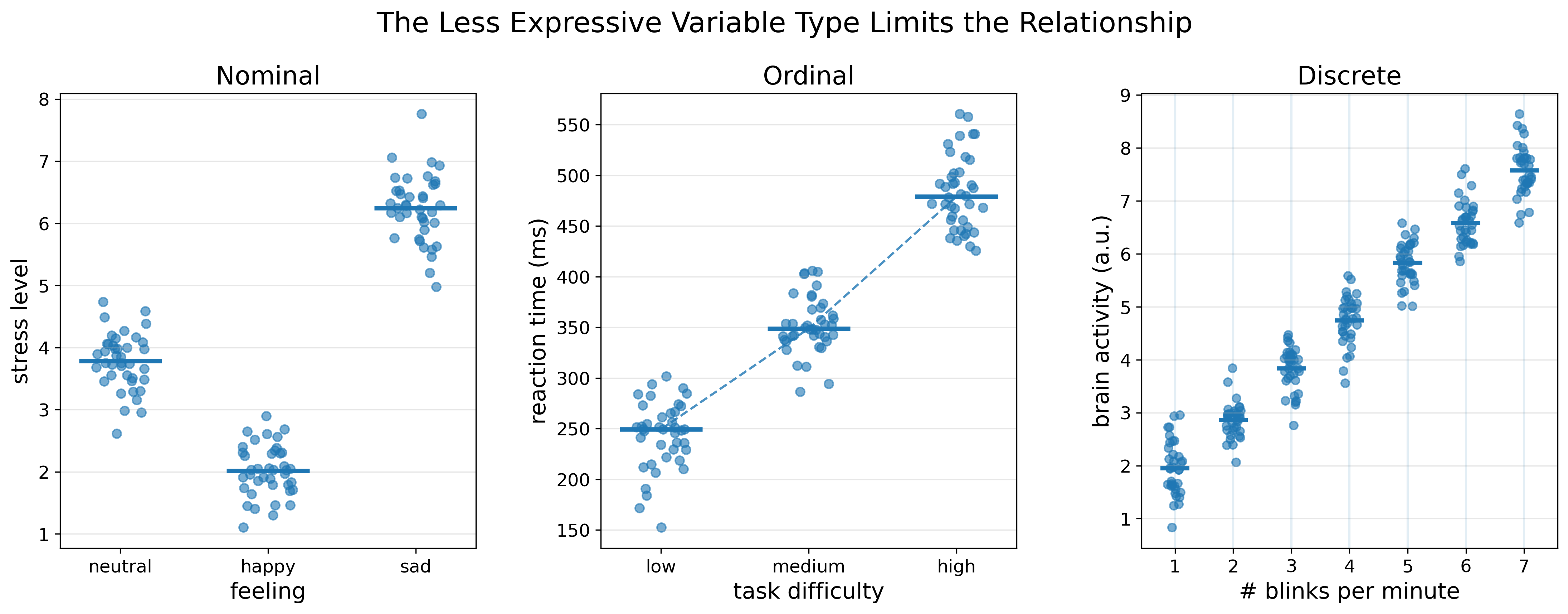
Short answer: when two variables interact, the mathematical relationship is limited by the least expressive variable type (Figure 11).
The easiest case, in my opinion, is when one variable is nominal and the other comes in any shape. Because nominal variables are the most restrictive of all types.
Once a variable is nominal, it already divides the other variable into spaces, and nothing more can be done.
For example, if \(X\) = feelings (i.e., nominal) and \(Y\) = stress level (i.e., ordinal), \(Y\) will immediately get distributed over \(X\) in a mixture of rule-based and threshold-based functions (e.g., if \(X=x\) then \(Y>y\)).
If \(Y\) = FMRI activity (i.e., continuous) or number of blinks per minute (i.e., discrete), the same thing will happen, except that the description of the \(Y\) splits can be more expressive. E.g., if \(X=x\) then \(Y \in [a, b]\) where a and b are the minimum and maximum values of the subset of \(Y\) under a given \(x\). Or if \(X=x\) then \(Y=\mu\) where \mu is the average of the values that fall under this \(x\).
So, nominal variables restrict the function to being rule-based, and allow flexibility only in how one chooses to describe the distribution of \(Y\) over \(X\).
The case where one variable is ordinal, and the other is quantitative is very similar to the nominal case. The ordinal variable splits the quantitative variable into spaces as well, with the only difference being that the spaces are ordered. E.g., \(\text{median}(Y \mid X=\text{low}) < \text{median}(Y \mid X=\text{medium}) < \text{median}(Y \mid X=\text{high})\).
The same happens when one variable is discrete and the other is continuous, although this case can easily trick the observer. In this case, both variables take ordered and equally spaced values, which makes them look very similar to each other. However, discrete variables still jump on the number line rather than covering it smoothly. This means that one cannot safely perform derivatives or gradients on them, and they will end up splitting \(Y\) into spaces, just as nominal and ordinal variables do.
\(Xs\) and \(Ys\)
So far, I have been contemplating the case of only two variables. But the problem is notoriously bigger than this.
In supervised machine learning, the typical setup is that one has multiple \(Xs\) to infer \(Y\) from. The equation is
If the setup is multi-task learning, then one has multiple \(Ys\) as well, and the equation becomes
\[y_1 = f_1(x_1, x_2, \dots, x_n),\text{ }y_2 = f_2(x_1, x_2, \dots, x_n), \dots\]In the previous two headers, I discussed how \(X\) and \(Y\) interact in different ways, but now the interaction happens at a bigger scale.
Each \(X_i\) can indeed still interact with \(Y\) in the ways specified, but now each \(X_i\) can also interact with another \(X_j\) (including itself) to affect the result for \(Y\).
The bigger function \(y = f(x_1, x_2, \dots, x_n)\) can be broken down into the same linear, non-linear, and mixed functions specified at the beginning of this section.
But now one also considers the linear, non-linear, and mixed interactions between every two or more variables.
For example, considering two interacting variables \(X_1\) and \(X_2\) influencing \(Y\), the function \(f(x)\) gets expanded into shapes like the following:
\[f(x)=x_1x_2,\text{ }f(x)=(x_1x_2)^a,\text{ }f(x)=\log(x_1)\log(x_2),\dots\]All these possible functions compete together as an accumulation, and the surviving functions get to make the final function for \(Y\):
\[y = w_1f_1(x_1) + w_2f_2(x_2) + w_3f_{12}(x_1,x_2) + w_4f_{11}(x_1^2) + \dots\]Where each \(f_i(x)\) represents one possible relationship and \(w_i\) corresponds to the weight of this relationship in affecting the final output of \(Y\). Similar to Figure 5, the data chooses which relationships survive and with which weights.
Figure 12 below shows how different transformations influence the prediction of \(Y\), and how the final relationship between \(X_1\), \(X_2\), and \(Y\) turns out.
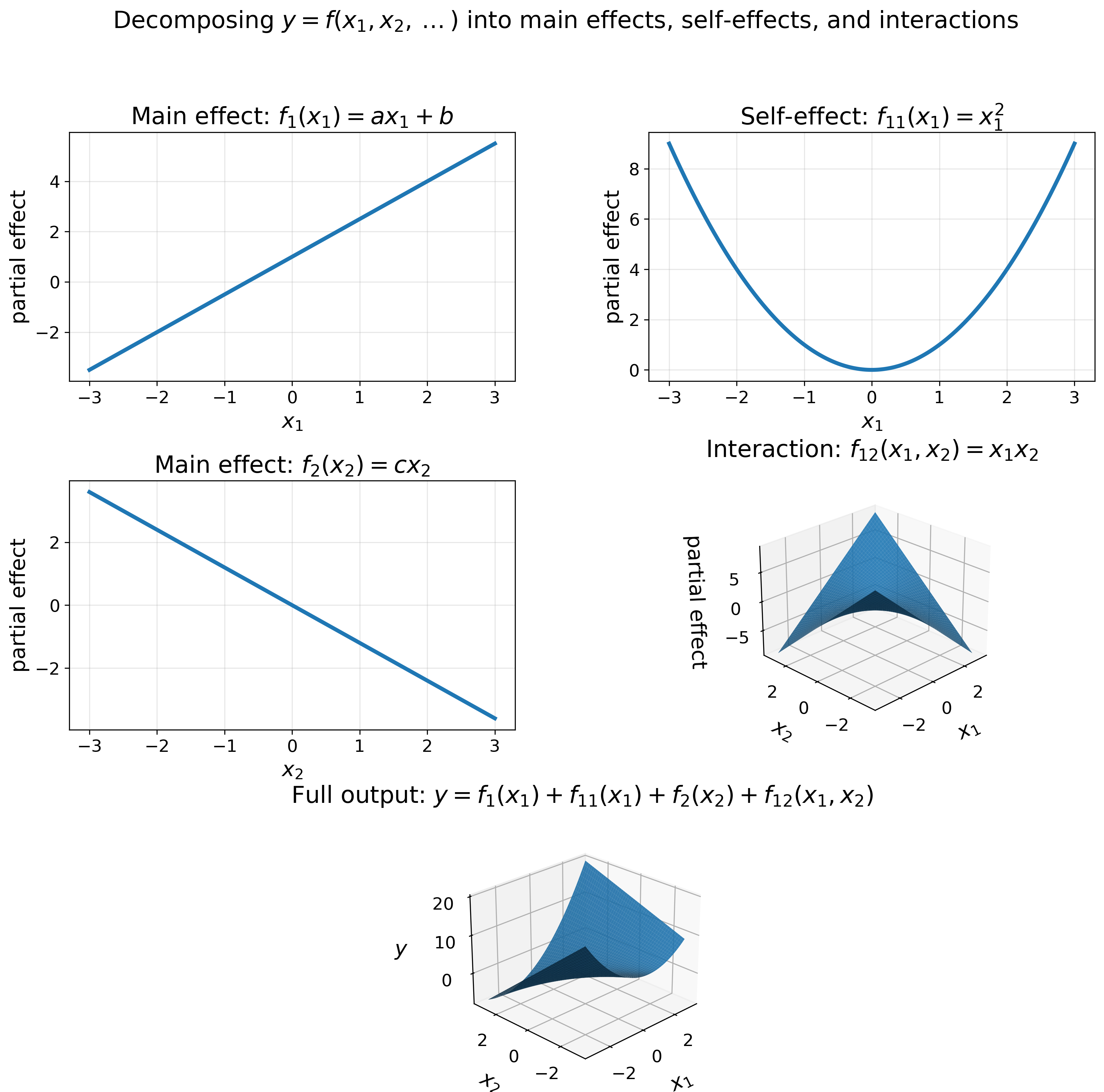
With such an explosion, the human is no longer capable of mindfully staying in the loop, and the task gets delegated to a machine with powerful memory designed for the task.
Even when the machine is powerful, if the size of \(Xs\) spans from hundreds to thousands, exploring all possible relationships can still be infeasible.
When the number of variables and the possible interactions between them explodes like this, it becomes even more important to keep track of the variable types. This will be one’s guardrail for limiting this explosive space.
One can introduce rules or algorithms to identify and respect the type of each variable and the math it gets access to.
For example, the nominal variables within \(Xs\) become default limiting factors because they inevitably split the space of any other variable they interact with, and one cannot do anything about it. If such nominal variables are indeed important for understanding the problem, then one is bound to respect how they split the space of the other variables.
If a variable is nominal or ordinal but takes the shape of a discrete variable, such as replacing low, medium, high with 1, 2, 3, this can be tricky for both the observer and the model. The latter gives the notion that \(2-1=1\), but in reality one does not know what the result of medium - low is.
If a variable is discrete, one needs to be careful when applying calculus to it because many models that deploy calculus assume continuity and smoothness.
The continuity assumption leads to learning functions where it is possible for a discrete variable to take a value like 1.34, although this is not possible. This artifact might or might not be harmful.
Smoothness assumes that points in a variable near each other must lead to similar effects on another variable, but the jumping nature of the discrete variable can encode abrupt jumps in another variable. A smooth function will punish such jumps even though they represent the truth (Figure 13).
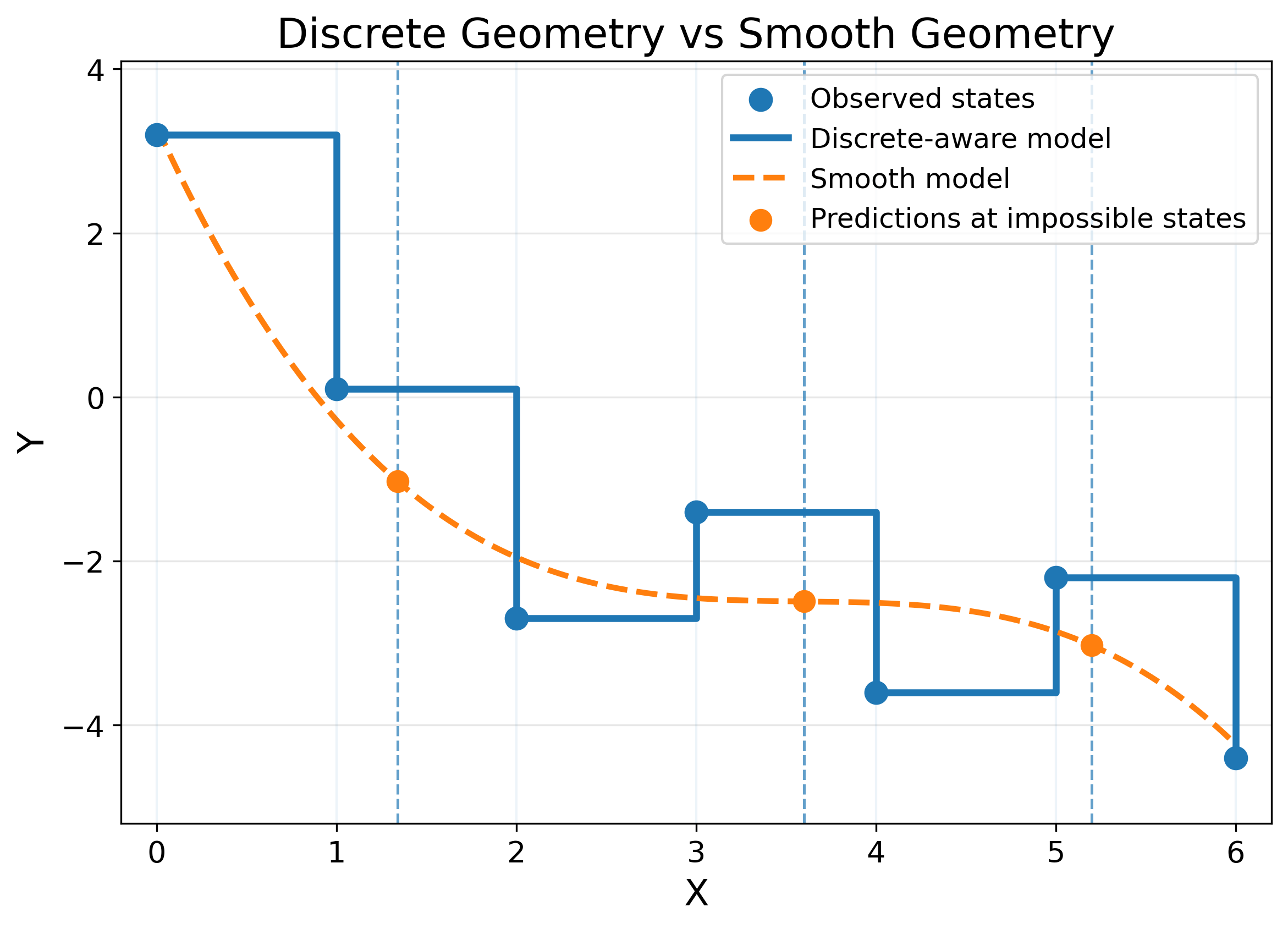
In this section, I am mainly concerned with how the type of variables can shift my thinking about which model to use. And it led me to realize that it is about variable geometry.
Most current machine learning algorithms (as will be discussed in a later post) rely on Euclidean geometry, which is the geometry of continuous variables. Yet the reason that got me into this topic initially was realizing that most of the variables I deal with in my PhD work are not continuous!
Different worlds of functions (frameworks)
Besides the types of variables affecting what math a function can use, there is still another factor that shapes what it can look like.
This time, the factor is related to the conceptual framework of the person searching for it. It is what this person assumes about this function, and therefore how to approach it.
I came to think of these frameworks as defining different views of the same function. Two of them are fundamental: deterministic and probabilistic, and the rest follow from them but with additional conceptual assumptions: causal, predictive, generative, and agentic.
Deterministic frameworks
In the deterministic view, the researcher has an assumption about the problem, an assumption of structure.
The researcher “believes” that there is a unifying force tying the different variables of the problem together and leading to a deterministic function with a single outcome for each value.
Here, \(y\) will always have one and only one corresponding value for each input \(x\).
It also assumes that all variables needed for this structure are attainable; thus, the function itself is attainable.
To make this distinction clear, in another framework, the function will take the form
where \(\epsilon\) is a probability distribution representing the possibility of missing variables or mismatched assumptions.
In deterministic frameworks, one has already made the assumption that there must not be an \(\epsilon\).
The researcher’s job then turns into figuring out how to land this function.
As far as I can comprehend, this setup will mostly be applicable to physical and natural laws that one stumbles upon rather than contributes to. I can think of three setups leading to such deterministic functions:
- One designed the system themselves, and thus they assigned the function already (e.g., a simple case of a professor mapping exam grades from percentages to letters, or a more advanced case of someone developing their own algorithm).
- One has large i.i.d. data that is representative of a problem and covers all its facets, such that one can now find the function that describes this problem perfectly (e.g., calculating the circumference of a circle; initially, people did it empirically until the data hinted at the equation \(y = 2\pi r\)).
- One was inspired by a formula for how something works, and when it was applied to its context, it always gave the desired result (e.g., Newton’s second law or Einstein’s relativity equations).
Probabilistic frameworks
In the probabilistic view, the researcher accounts for cases where the system is missing components, and thus the answer is not reached perfectly but only partially:
\[y = f(x) + \epsilon\]Or the system itself is stochastic, meaning it does not give the same answer under the same observable conditions. In such cases, one calculates a probability distribution for the outcome \(Y\) given the current knowledge \(X\).
\[P(Y\mid X)\]This reads as follows: given \(X=x\), what are the possible values \(y\) to observe in \(Y\)? Figure 14 shows the difference between the deterministic view and the probabilistic view in its two facets: imperfect prediction and true stochasticity.
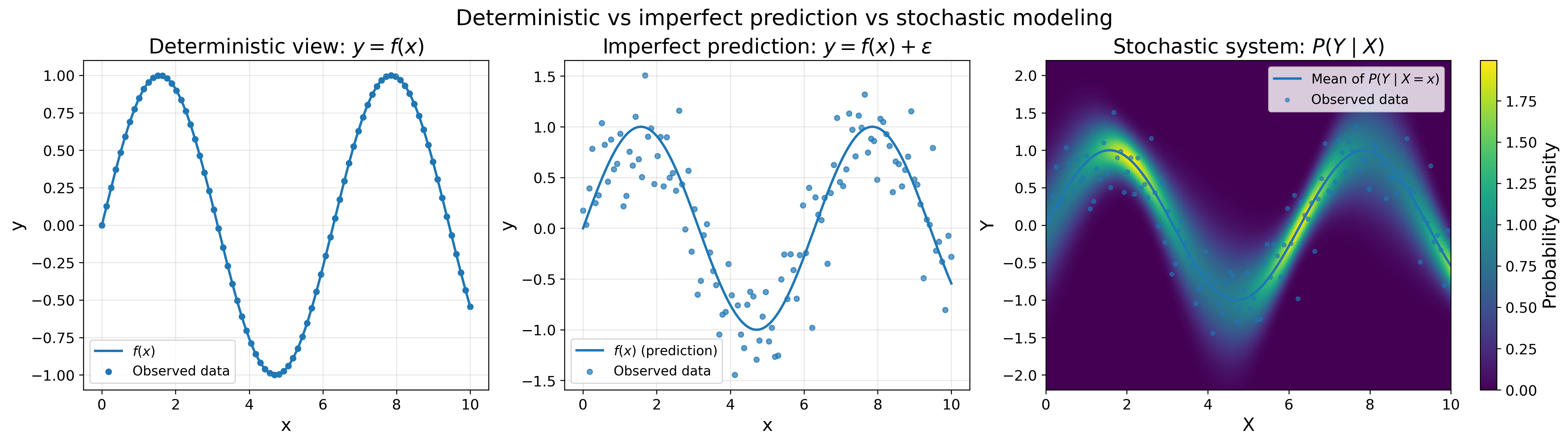
In this framework, one moves away from the certainty assumption in the deterministic framework and toward a system of uncertainty. I can think of the following cases where uncertainty is in the system, and thus probabilistic frameworks are more suited to it:
- The measurement of the variable \(Y\) is noisy. Therefore, even if the relationship is deterministic, one does not have the appropriate data to find it. In such a case, one knows that the goal is not to output a single value of \(y\), but rather an uncertainty measure around it (i.e., \(P(Y \mid X)\)).
- One example from chemistry is experimental procedures that rely on multiple factors, from well-calibrated equipment and well-maintained materials to well-handled execution, and even to the original assumption about the validity of the measuring process itself. When these steps are not accurate enough, we end up with noisy data, and the same measurement for a compound is not reproducible across experiments. Therefore, the function used to map this relationship would also respect this uncertainty and infer probabilities rather than single values.
- The variables \(X_1, X_2,\dots, X_n\) used to infer the outcome \(Y\) are not suitable or are incomplete. In such cases, the relationship between \(X\) and \(Y\) can only be approximated to the best allowed by the information provided by \(X\) (i.e., \(y = f(x) + \epsilon\)).
- The never-getting-old example from cheminformatics is the struggle to find sufficient representations for our molecules. I recall Tony, the medicinal chemist postdoc in our group, once telling me in a discussion that chemistry is the science of the electron. If one finds the right functions to calculate the quantum states of electrons, one has chemistry figured out. But because we are not there yet, we can only represent molecules using variables that approximate these quantum functions, probably not in a great way.
- The function \(f(x)\) used to map between \(X\) and \(Y\) is not appropriate. This happens when one uses the wrong assumptions about the relationship and ends up measuring or approximating it using an inappropriate, or simply less ideal, function (i.e., \(y = f(x) + \epsilon\)).
- This was shown in Figure 13 when a smooth function was used to model a non-smooth relationship. The smooth function will be close to correct in some places, and completely off in others.
- The system itself is truly stochastic. It is not about noisy measurements, missing variables, or mismatched functions. The system gives different answers even if the observable conditions are the same (i.e., \(P(Y \mid X)\)).
- This is, of course, a very well-known phenomenon in quantum mechanics, such as calculating the position of an electron. One cannot determine the exact position of an electron, but rather the probability of finding an electron at some position.
I can think of another case that would conceptually fit this framework, but with a caveat, in my opinion.
- The variables \(Xs\) and/or \(Y\) do not span the full range of their possible outcomes, making the data incomplete.
- A loose example could be the relationship between molecular weight and aqueous solubility measured in LogS. Molecular weight can range from \(<100\) to \(>500\) daltons. If one measures LogS for light molecules only, one may find a linear relationship, but as the molecular weight increases, the relationship might start becoming non-linear.
This case contains incompleteness, as in the missing-variables or mismatched-assumptions cases. However, the incompleteness would be relevant only if one decided to use the function fitted on this specific range of both variables to infer other ranges.
Incompleteness is not inherent to the function or the data, but rather to how the person applies the function in the future.
Causal frameworks
Causal frameworks are concerned with the mechanics of the relationship; they ensure that a relationship, deterministic or probabilistic, is obtained for the “right” reason.
To explain what “right” reason means, I feel like I need to split the framework into two phases: pre-data-explosion and post-data-explosion.
In the pre-data-explosion phase, data was scarce and costly, obtained through a carefully designed experiment to measure variables of interest. Only after collecting data could one attempt to find the function describing the relationship between such variables.
The next question would intuitively be: which variables should be measured?
Depending on the task’s difficulty, a researcher can have freedom in the variables to choose from. But I would assume that any experiment requiring human labor would eventually call for careful consideration to make the measured variables as relevant as possible to the problem under investigation, and as variables that are “believed” to be instrumental to it.
This “belief” is at the heart of the causal framework for this phase. A researcher relies on prior established knowledge, or on their own expertise stored in their brain or gut, to select the variables \(X\) and \(Y\).
Once \(X\) and \(Y\) are selected, one performs a scientific experiment to generate data that would help find the function linking them together.
This experiment would follow the good old scientific principle:
- Intervene by changing \(X\) to one’s desired value.
- Watch whether \(Y\) changes as \(X\) changes.
- Pay attention to confounding factors to the best of one’s knowledge and experience (i.e., an uncontrolled third variable \(Z\) that might be the main reason behind the change, not \(X\)).
- Examine the change in \(Y\) to judge whether it is enough to conclude a plausible relationship with \(X\) (i.e., \(P(Y \mid do(X))\)) (Figure 15).
- If changing \(X\) leads to the same change in \(Y\) every single time (i.e., \(P(Y=f(X) \mid do(X)) = 1\)), then a causal relationship is established, and the relationship is deterministic.
- If changing \(X\) leads to a distributional shift in \(Y\) (i.e., \(P(Y \mid do(X)) \neq P(Y)\)), then a causal relationship is established, and the relationship is probabilistic.
- If \(Y\) does not change (i.e., \(P(Y \mid do(X)) = P(Y)\)), then the relationship is not established, and the experiment is open for exploration again.
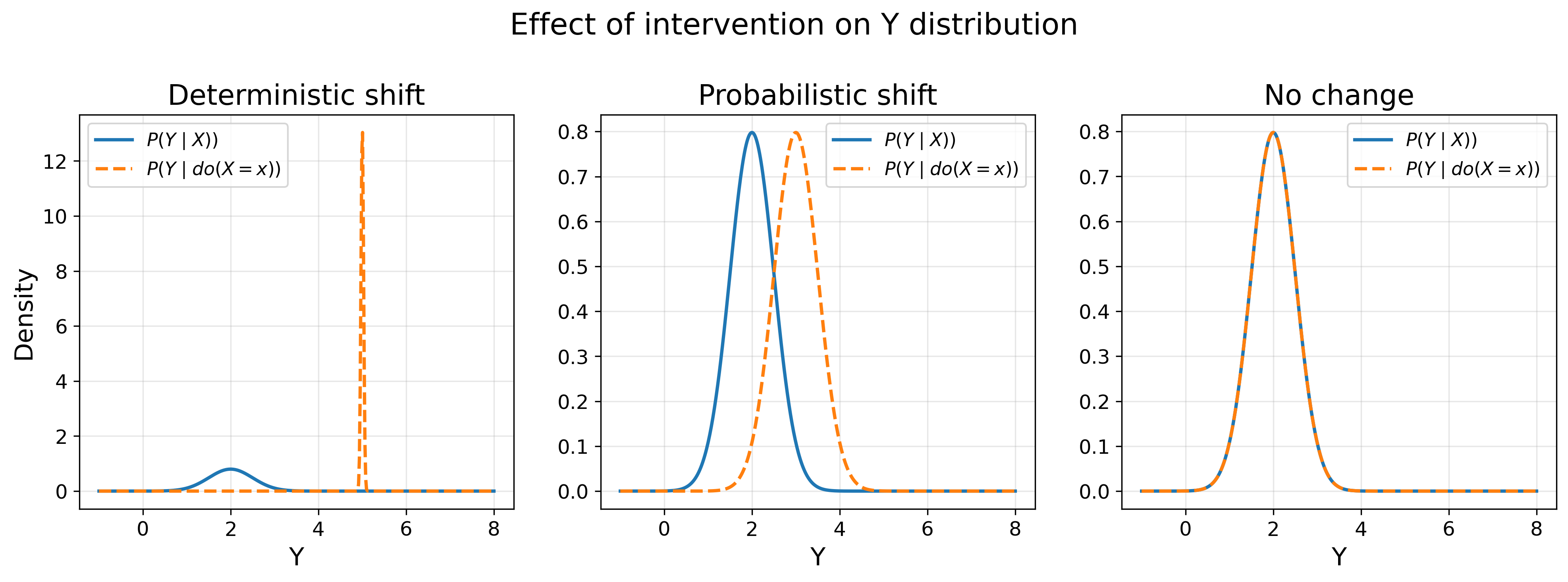
Once \(X\) is established to influence \(Y\), one can then start searching for the function (deterministic or probabilistic) that models this relationship.
In the post-data-explosion phase, the scene changes as follows:
- A statistician starts with loads of already measured or calculated variables that might or might not be instrumental to the problem.
- A plethora of functions can be applied to different variables to establish relationships between them.
- The researcher ends up with the best function to describe how \(X\) relates to \(Y\).
But one needs to always remember the never-old wisdom:
Correlation does not imply causation
One can have two variables and find a function that describes them (almost) perfectly, but without a “logical justification” as judged by an expert on the problem.
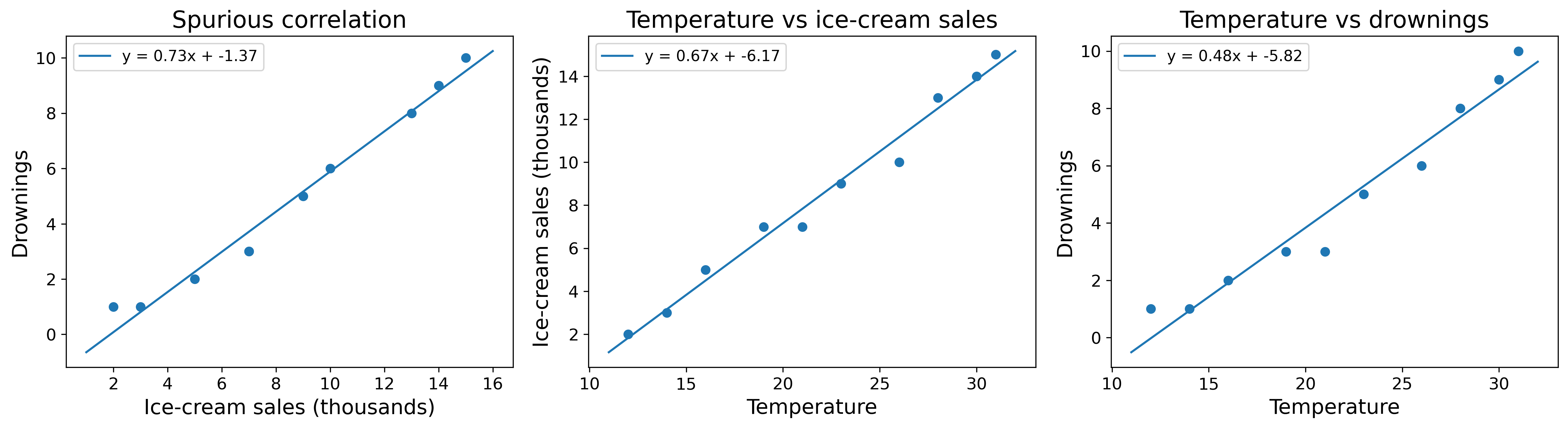
A very famous example is the number of ice creams sold per month (which I will call \(X\)) versus the number of drownings in the same months (which I will call \(Y\)).
The relationship turned out to be \(y = 0.73x-1.37\) (Figure 16). Meaning, if one knows the ice cream sales of a month, one can predict how many drownings will occur.
But I hope one can easily stop and say: Wait a minute! I do not understand what would make ice cream sales relate to drownings! Is something missing?
And indeed, the missing piece was a third variable, \(Z=\text{temperature}\). Temperature turned out to be a confounding factor that explains how ice cream sales and drownings could have been related.
Higher temperatures call for more ice cream consumption as well as more swimming. More swimming leads to more possibilities of drowning.
So, if one was interested in understanding the main cause behind drowning and used ice cream sales instead of temperature, one would find a perfect function to tie them together.
But it was the human’s judgment of the physical and experiential world that made this relationship die in its infancy even though it perfectly described the observed data.
Therefore, a causal framework can be thought of as the framework of strong assumptions. A relationship is not permissible without validation of a logical connection between the variables.
To ensure causality in the data-explosion era, one would be bound to rely on the expert’s assumptions about a problem to:
- Spot whether some variables are confounding.
- Spot whether policies and practices led the data to look the way it did, rather than reflecting an honest view of reality.
These assumptions can then be formalized in explicit algorithms that scan the data to find them and handle relation permissibility through logic.
One example of such algorithms is causal graphs. In this algorithm, logical relationships get encoded in directed acyclic graphs (DAGs) that help determine confounding factors.
In the drowning example, if one used the variables \(X_1=\text{ice cream sales}, X_2=\text{swimming}, X_3=\text{temperature}\) to predict the variable \(Y=\text{drowning}\), the DAG for this problem would look like this:
Temperature → Ice cream sales
Temperature → Swimming → Drownings
And this graph would label temperature as a confounding factor.
Predictive frameworks
In this framework, one realizes the slow nature of the causal framework relative to the amount of data available nowadays, dislikes it, and decides to change it.
The predictive framework tries to answer a single question: does this data help me make good predictions about the future?
At first glance, this question might not feel that different from the other frameworks. If one suspects causality and finds the relationship, then one can easily predict the future within the certainty level of that relationship.
So, where is the novelty?
Well, in the causal framework, one needed to emphasize the phrase correlation does not imply causation and use it as a safeguard to filter “spurious” relationships.
But in the predictive framework, one need not worry about spuriousness.
In the predictive framework, if a relationship works well enough to predict the next outcome, one accepts it, celebrates it, embraces it, and moves on. DO NOT SEARCH FOR LOGIC!
Predictive frameworks are not meant to spot or explain logic; they are goal-oriented, where the end justifies the means.
They try to find the same probabilistic function as before:
\[P(Y \mid X)\]
The only difference is that now \(X\) represents whatever variables one has rather than a “carefully curated set of variables” (Figure 17).
To make this more tangible, remember the ice cream sales versus drownings example. A human was not satisfied by this relationship because it did not make sense given physical and experiential logic, which made them look for a “more plausible” connection to drowning.
But the thing is, if predicting drownings was the goal, then ice cream sales do predict it.
As long as people buy more ice cream and swim more as the temperature gets higher, the relationship between ice cream sales and drowning would still work.
The only thing to change would be our intellectual satisfaction as human beings, not the result.
So, the predictive framework does not provide changes to the mathematical or functional world, but rather an epistemological and philosophical stance.
The predictive framework forces one to think about the end goal, because this end goal is the only thing that determines which route to take!
- If my end goal is to satisfy my curiosity by understanding the mechanics of the problem, then I will use causal frameworks.
- It is slower, and requires lots of communication between experts, but this is the road to “understanding.”
- If my end goal is to manipulate the system and tweak it to my desire (e.g., optimizing a molecule for drug development), then I will “eventually” need to “understand” the problem. Then I might use either the causal framework only, or a mix of causal and predictive frameworks.
- This mixing would usually happen by starting with causality, using it for predictability, learning something new about the system, integrating it into the causal framework, using it again for predictability, and repeating.
- If I trust the system to be static and well-behaved, and I am interested in working around it rather than understanding or manipulating it, then predictive frameworks are all that I need.
In my opinion, any attempt to start with a predictive framework and then post-hoc it for causality would be a needlessly redundant task.
When one tries to extract causality from predictive frameworks, one is basically doing the same work one would have done by using the causal framework from the beginning.
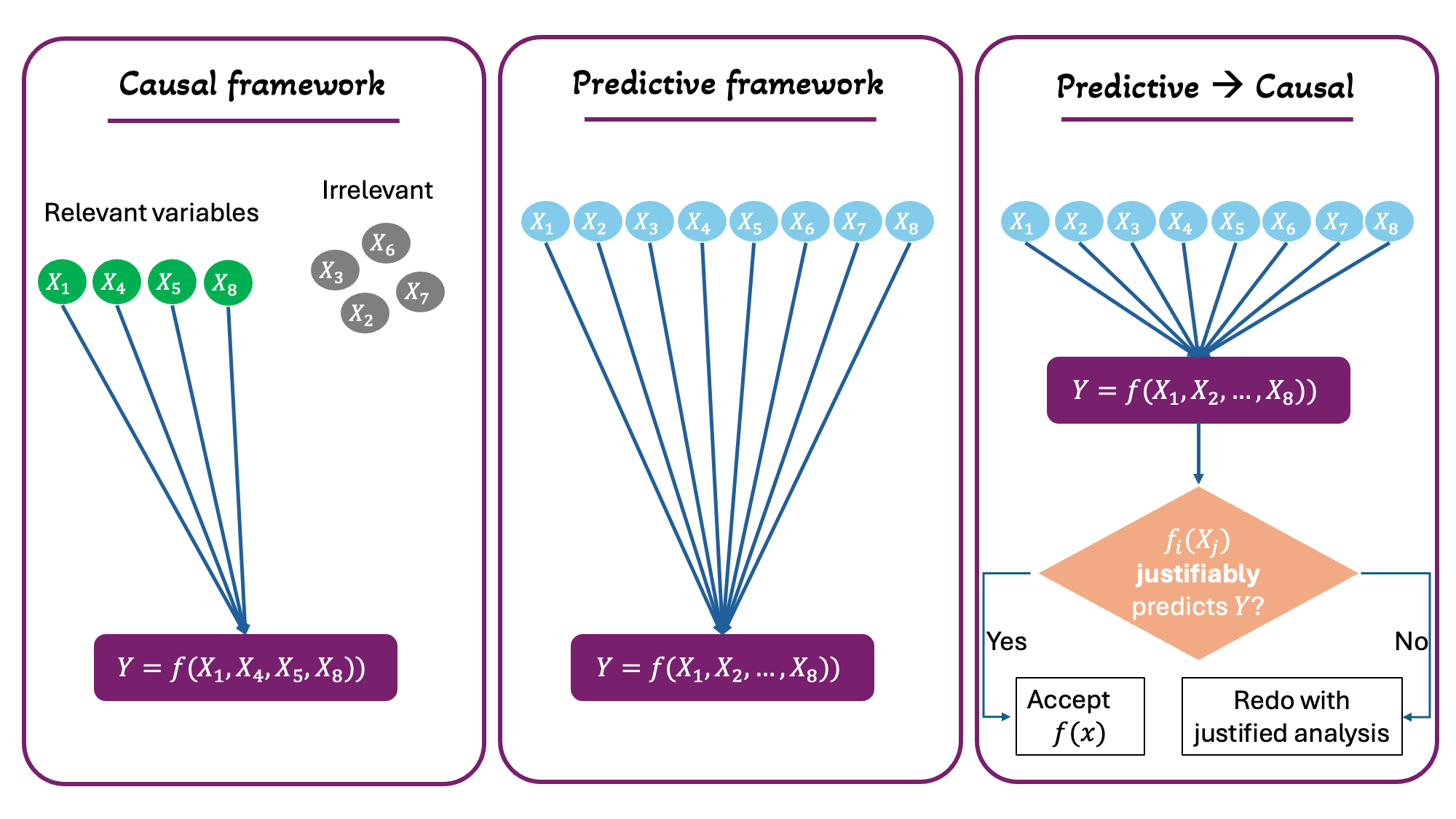
To make this redundancy clear, let us check this scenario. If one used 10 variables (\(X_1, X_2, \dots, X_{10}\)) to predict \(Y\), one has three options, and one of them is redundant (Figure 17).
- The researcher performs sanity checks on these variables to see what is logical for predicting \(Y\), then selects only those for prediction → Causal framework.
- The researcher uses all variables—without vetting them—to predict \(Y\) and simply trusts the process → Predictive framework.
- The researcher uses all variables—without vetting them—to predict \(Y\), gets the relationships between each \(X\) and \(Y\), then checks whether each relationship is actually permissible → Predictive followed by causal (i.e., redundant).
Generative frameworks
In my opinion, a generative framework is a deeper version of predictive frameworks. It inherits the same guiding principle:
Trust the data and do not look for logic.
However, the task required of the model becomes significantly harder.
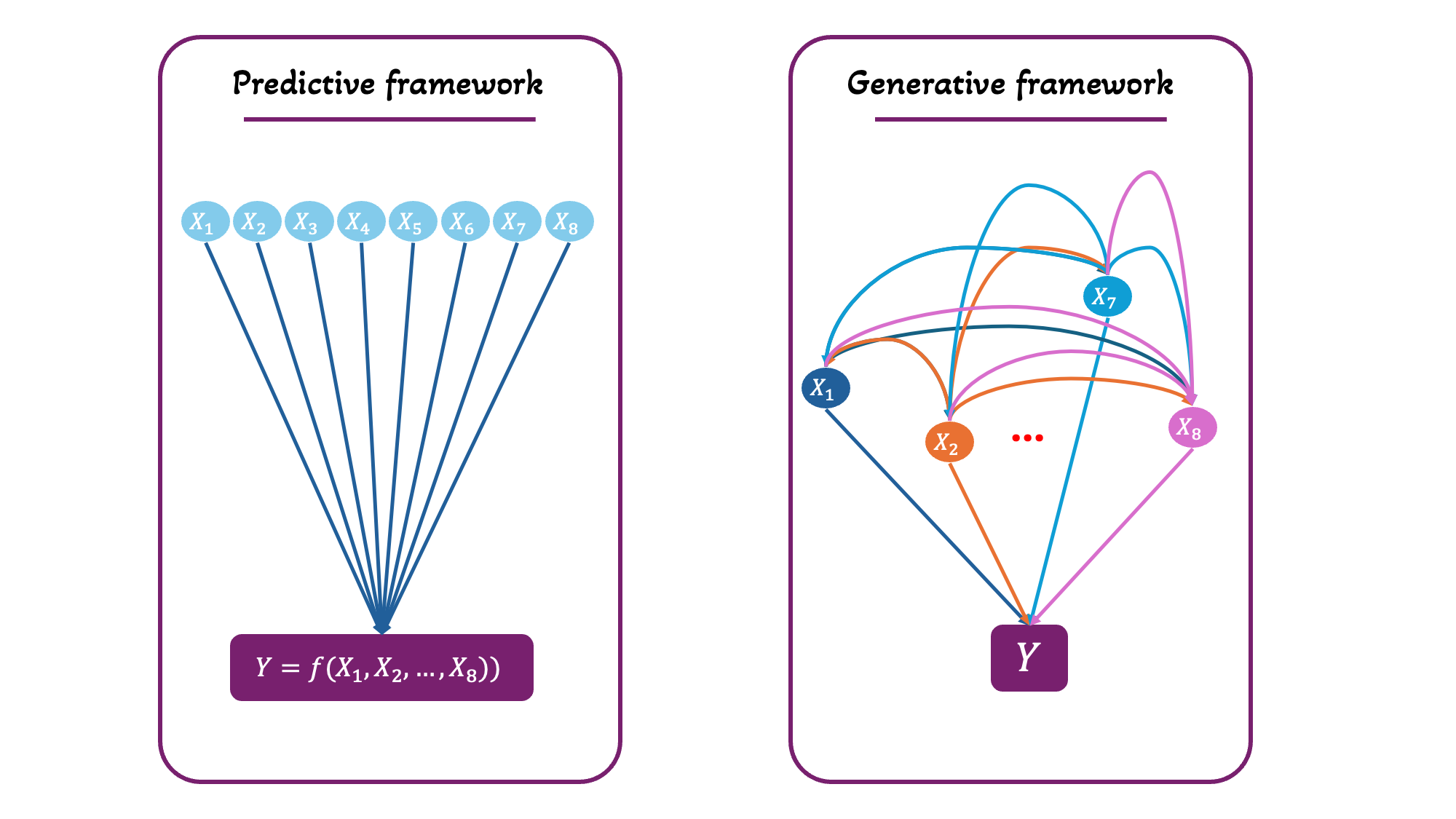
In predictive frameworks, the function to be predicted is \(P(Y \mid X)\); i.e., when one sees \(X=x\), what is the probability of seeing a specific \(y\) value from \(Y\)?
In generative frameworks, the function is
This is a joint probability distribution of the variables. The model does not only learn \(Y\) conditional on \(X\), but also each \(X_i\) conditional on the other \(Xs\).
In predictive frameworks, one only needed to find the function \(y = f(x)\), but in generative frameworks, one also wants to find all the functions \(x_i = f(y,x_{j \neq i})\) (Figure 18).
The goal of generative frameworks is to create a function that would reproduce the data, or generate new data that would look indistinguishable from the original. This comes from learning all bidirectional relationships in the data.
For example, one may have a dataset of molecules and corresponding aqueous solubility measurements. A generative model would learn all possible relationships between molecules, and between molecules and their aqueous solubility. Once this is achieved, a generative function can then generate new molecules with a desired aqueous solubility range.
While this framework feels powerful and flashy, one needs to be aware of the amount of possible spuriousness that can be propagated within it.
The predictive framework already relaxes the condition of logical consistency and allows for \(Xs\) to be redundantly or carelessly linked to \(Y\). Now, it additionally allows for \(Xs\) to be redundantly or carelessly linked to each other.
Because the model attempts to capture all statistical dependencies in the data, any coincidental or noisy relationships may be absorbed and reproduced by the model.
I will argue again that manipulating a system requires the implication of causality when intervening in it, if one wishes to walk in rationally grounded steps rather than irrationally independent ones3.
Here, in the generative framework, the goal is usually manipulation. It is to generate or simulate data similar to the original instead of producing it through labor.
Excluding causality relaxes the task and makes it easier and faster, but how far can one get while blindfolded?
Since generative frameworks have been exploding only recently, work on integrating them with causality is still in progress.
Agentic frameworks
I believe an agentic framework is the natural follow-up aspiration to the previous ones. If one has found a way to make functions that predict and generate, it becomes time to “delegate.”
The way I see it, there has always been a higher goal above whatever the previous frameworks were doing.
A causal framework tries to understand, a predictive framework tries to forecast, and a generative framework tries to reproduce reality.
But why are humans eager to understand, forecast, or reproduce systems?
I believe it has always been about control: controlling the environment, controlling the future, and eventually creating the environment and the future.
So, the end goal is not to understand, forecast, and reproduce. It is to use the knowledge and capabilities of these frameworks to propose policies and modifications to the system.
So far, the entity that uses this knowledge to propose policies and modifications has been strictly human. With agentic frameworks, one willingly delegates some of these decisions to an agent.
This agent operates within an environment defined by humans. It uses the data provided, explores the set of actions available to it, and proposes policies within the limits of the system it can observe and interact with.
The central question of agentic frameworks becomes: which actions should be taken to maximize a desired outcome over time?
Instead of predicting variables, the variables become a dynamic environment, and the agent must now learn a policy for action over different states of the environment.
The mathematical representation of this policy is
\[\pi(a \mid s)\]It reads as follows: given that the environment is in state \(s\), what is the probability of taking action \(a\)?
So, for agentic frameworks, one needs to provide a set of actions that would then be mapped to an environment. And the probability of each action will change as the state of the environment changes.
An example to lock this in can be a self-driving car.
- Agent = car
- Current state of the environment = a wall is approaching
- Possible actions = [turn left, turn right, brake]
The agent will need to assign a probability to each action given the current situation. These probabilities would be learned by generating different situations and environments and mapping which action gives the best results over time.
Again, an agentic framework feels magical, but still, as with each previous framework, the human is giving something up in exchange.
In predictive frameworks, humans gave up logical coherence.
In generative frameworks, humans gave up concrete goals (i.e., generate something similar synthetically rather than create something novel manually) and doubled down on logical coherence.
And here, in the agentic framework, humans are slowly letting go of their agency, their direct control over decision-making4.
The connection to ML and cheminformatics
While I have not discussed a single ML model like linear regression, random forest, or neural network, this post has made it much clearer for me to navigate such models.
The next technical post will focus on viewing such models in light of what has been discussed in this post.
Cheminformatics is an applied science branch that relies on advances in the ML field translating into advances in the chemical field.
However, this post also made it clear to me that transferability between the two domains is not as easy as one might think.
The math is general, but the application is strictly subjective to each problem, its variables, the relative knowledge available so far, and the researcher’s own goals.
In the next technical post, hopefully I will be able to explore how I shall think about applying ML models to a cheminformatics task after the current clarifications I went through.
In the field of statistics, it’s called distribution. Check out this post to know more about a variable/distribution’s concepts. ↩
Any letter that is not defined represents a constant. ↩
Not claiming that either is better. It is merely a matter of preference. Both would lead to results eventually, in my opinion, but I have my own preference for using one over the other :) ↩
Also, not claiming that this is bad or good. Only mentioning the cost of an action so one is aware of it. Choosing whether to take this action would be up to the person in charge of making it :) ↩